大模型RAG中的分块策略
分块策略在检索增强生成(RAG)方法中起着至关重要的作用,它使文档能够被划分为可管理的部分,同时保持上下文。每种方法都有其特定的优势,适用于特定的用例。
将大型数据文件拆分为更易于管理的段是提高LLM应用效率的最关键步骤之一。目标是向LLM提供完成特定任务所需的确切信息,不多也不少。
“我的解决方案中应该采用何种合适的分块策略”是LLM实践者在构建高级 RAG 解决方案时必须做出的初始和基本决策之一。
关于LangChat
LangChat 是Java生态下企业级AIGC项目解决方案,集成RBAC和AIGC大模型能力,帮助企业快速定制AI知识库、企业AI机器人。
支持的AI大模型: Gitee AI / 阿里通义 / 百度千帆 / DeepSeek / 抖音豆包 / 智谱清言 / 零一万物 / 讯飞星火 / OpenAI / Gemini / Ollama / Azure / Claude 等大模型。
- 官网地址:http://langchat.cn/
开源地址:
什么是分块?
分块涉及将文本划分为可管理的单元或“块”,以实现高效处理。这种分割对于语义搜索、信息检索和生成式 AI 应用等任务至关重要。每个块都保留上下文和语义完整性,以确保结果连贯。
2. 分块技术及其策略
各种分块技术根据文本结构和应用需求满足特定需求:
- 固定长度分块:根据标记、单词或字符将文本分割成统一的大小。这种方法计算效率高,但可能在边界处切断有意义的上下文。
- 基于句子的分块:按句子分割文本,保留语法和上下文完整性。非常适合对话模型,但可能对较长的文本效率不高。
- 基于段落的分块:按段落分组文本,保持主题上下文。适用于结构化文档,但可能对精细调整的任务失去粒度。
- 语义分块:专注于按意义分组文本,而不是结构。这确保了语义连贯性,但增加了计算开销,因为它需要深入的语言理解。
- 滑动窗口分块:使用重叠窗口对文本进行分段,减少块边界处的信息损失。它确保更好的上下文保留,但会增加内存和处理成本。
- 文档分块:将整个文档视为一个单一块。这种方法对于保持整体上下文有效,但由于内存限制,可能不适用于大型文本。
3. 分块优化关键策略
为了最大化分块的优势,采用以下策略:
- 重叠块:包括块之间的某些重叠可以确保在段落之间不会丢失关键信息。这对于需要无缝过渡的任务尤其重要,如对话生成或摘要。
- 动态块大小:根据模型的容量或文本的复杂性调整块大小可以提升性能。较小的块适合 BERT 等模型,而较大的块适用于需要更广泛上下文的生成任务。
- :递归或多级分块允许处理复杂的文本结构,例如将文档拆分为章节、节和段落。
- 向量化的对齐:分块技术的选择对检索系统中的向量表示有显著影响。句子转换器和 BERT 或 GPT 等嵌入通常用于与分块粒度对齐的最佳向量化
4. 优点与局限性
- 好处:
- 增强上下文理解。
- 支持 RAG 系统中高效的索引和检索。
- 保持生成模型中更好的准确性,语义连贯性。
- 限制:
- 计算上对语义和重叠分块较为昂贵。
- 需要调整以平衡上下文保留和处理效率。
5. 应用场景
分词在以下方面被广泛使用:
- 检索系统:在搜索引擎或聊天机器人中检索回答查询的相关片段。
- 生成模型:保持文本生成的上下文连贯。
- 学术和法律研究:确保对结构化和复杂文档进行详细、有意义的分段。
通过采用适当的分块策略,从业者可以提升检索和生成系统的性能,在计算资源和上下文准确性之间取得平衡。
1. 固定长度分块
固定长度分块将文本分割成指定字符数或词数的块。这种方法简单直接,但往往存在将有意义的内容分割开的风险,导致上下文丢失。
如何工作:如何工作
- 该方法根据预定义的长度(例如,单词数、标记或字符数)将文本划分为均匀的块。
- 例如,一个包含 100 个单词的段落可能被分成十个 10 个单词的片段。
优势:
- 简洁性与计算效率。
- 适用于结构化文本或当上下文边界不是关键时。
缺点:
- 可能会在块之间分割句子或想法,导致语义连贯性丧失。
示例:示例:
- 文本分块通过将文本分解成部分来提高检索。
- 固定长度分块(每块 10 个字符):
- 块 1:“Chunking i”
- 块 2:“提高 re”
- 块 3:“通过”检索
Input: "The quick brown fox jumps over the lazy dog. It is a bright sunny day."
Chunk Size: 10 characters
Chunks:
1. "The quick "
2. "brown fox "
3. "jumps over"
4. " the lazy"
5. " dog. It"
6. " is a bri"
7. "ght sunny"
8. " day."- 影响:分割句子或思想会导致语义连贯性丧失。
代码示例
def fixed_length_chunk(text, size):
return [text[i:i+size] for i in range(0, len(text), size)]2. 语义块切分
文本根据语义连贯性分成块,确保每个块都是一个有意义的单元。这通常需要使用嵌入来找到逻辑边界。
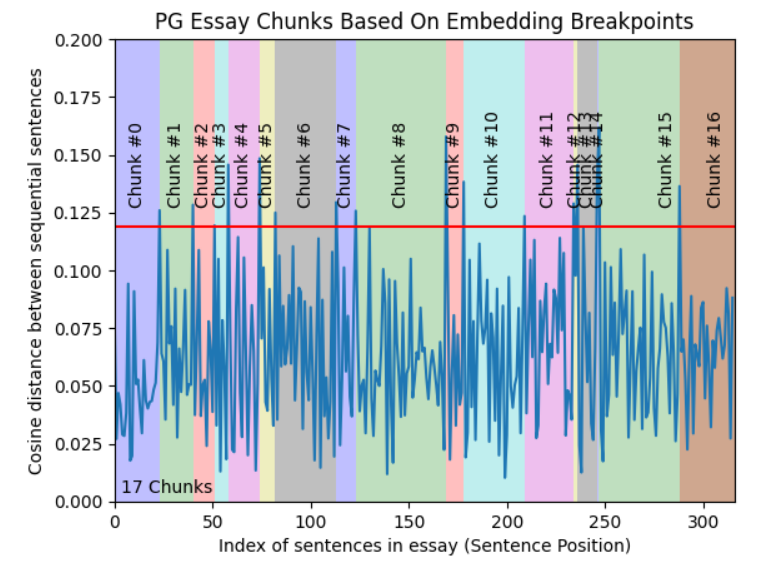
如何工作:如何工作
- 文本根据语义连贯性而非固定大小进行划分。
- 使用自然语言理解(NLP)来识别逻辑断点,如句子或主题边界。
优势:
- 保留每个片段的意义和上下文。
- 提升检索增强生成(RAG)任务的准确性。
缺点:
- 计算成本高,因为它需要语义解析。
示例:示例:
- AI 研究涵盖各种主题。机器学习专注于模式。
- 语义块:
- 块 1:“人工智能研究涵盖各种主题。”
- 机器学习专注于模式。
Input: "The quick brown fox jumps over the lazy dog. It is a bright sunny day."
Chunks:
1. "The quick brown fox jumps over the lazy dog."
2. "It is a bright sunny day."- 影响:通过保留信息的逻辑流程来提高检索准确性。
- 代码示例
from sentence_transformers import SentenceTransformer
def semantic_chunk(text, max_tokens, model):
sentences = text.split('. ')
chunks, current_chunk = [], ""
for sentence in sentences:
if len(current_chunk) + len(sentence) <= max_tokens:
current_chunk += sentence + ". "
else:
chunks.append(current_chunk.strip())
current_chunk = sentence + ". "
if current_chunk:
chunks.append(current_chunk.strip())
return chunks3. 递归字符分块
初始块基于字符限制创建。如果它们太大,则递归地分成更小的、具有语义意义的单元(例如,句子)。
如何工作:如何工作
- 最初,根据字符限制(例如,500 个字符)创建大块内容。
- 如果一个块超过了限制,它将被递归地分割成更小的有意义的单位,例如句子。
优势:
- 保留语义完整性,同时遵守尺寸限制。
- 非常适合存在 API 限制的情况(例如,OpenAI 的令牌限制)。
缺点:
- 递归处理会增加计算时间。
示例:示例:
- 文本分块将文本分解成更小的部分。此方法增强了检索。
- 递归字符限制(20 个字符):
- 文本块 1:“分块处理文本”
- 块 2:“分成更小的部分。”
- 块 3:“此方法增强”
- 块 4:“检索。”
示例:示例:
Input: "The quick brown fox jumps over the lazy dog. It is a bright sunny day."
Step 1: Chunk by character size (50).
Step 2: Further divide large chunks into sentences.
Chunks:
1. "The quick brown fox jumps over the lazy dog."
2. "It is a bright sunny day."影响:平衡块大小和连贯性。
代码示例
def recursive_chunk(text, char_limit):
if len(text) <= char_limit:
return [text]
midpoint = len(text) // 2
for i in range(midpoint, len(text)):
if text[i] in '.!?':
return [text[:i+1].strip()] + recursive_chunk(text[i+1:].strip(), char_limit)4. 自适应分块
动态调整块大小,根据内容的复杂度或重要性,利用自然语言处理技术识别逻辑终点。
如何工作:如何工作
- 动态调整块大小,基于内容复杂度。
- 使用先进的自然语言处理技术来查找逻辑端点。
优势:
- 平衡计算效率和语义连贯性。
- 有效处理复杂和可变长度的内容。
缺点:
- 实施复杂性。
示例:示例:
- “简单想法适合小块。复杂概念需要更大的块。”
- 自适应块
- 块 1:“简单想法适合小块。”
- 块 2:“复杂概念需要更大的块。”
示例:示例:
Input: "The quick brown fox jumps over the lazy dog. It is a bright sunny day."
Output:
1. "The quick brown fox jumps over the lazy dog."
2. "It is a bright sunny day."影响:适应不同类型的文档,提高混合内容情况下的性能。
代码示例
def adaptive_chunk(text, nlp_model):
doc = nlp_model(text)
chunks = []
for sent in doc.sents:
chunks.append(sent.text.strip())
return chunks5. 混合分块
- 解释:结合固定长度和语义分块,允许在块大小上保持灵活性,同时保持语义连贯性。
如何工作:如何工作
- 结合固定大小和语义分块策略。
- 允许在保持上下文的同时调整块大小。
优势:
- 可定制以适应特定应用。
- 平衡精度与效率。
缺点:
- 需要仔细调整以避免冗余或失真。
示例:示例:
- “分块提高检索效率。灵活性对于精确度至关重要。”
- 混合块:
- 块 1:“分块提高检索。”
- 块 2:“灵活性对精度至关重要。”
示例:示例:
Input: "The quick brown fox jumps over the lazy dog. It is a bright sunny day."
Chunk Size: 10 words
Chunks:
1. "The quick brown fox jumps over the lazy dog."
2. "It is a bright sunny day."- 影响:针对既需要上下文又需要计算效率的系统进行了优化。
代码示例
def hybrid_chunk(text, word_limit, semantic=True):
words = text.split()
chunks = []
for i in range(0, len(words), word_limit):
chunk = " ".join(words[i:i+word_limit])
if semantic and chunk[-1] not in '.!?':
chunk += '.'
chunks.append(chunk.strip())
return chunks6. 重叠分块
块重叠一定间距,确保边界处不丢失上下文。
如何工作:如何工作
- 创建重叠块以保留边界之间的上下文。
- 确保一个块中的关键思想不会在块之间丢失。
优势:
- 保留更多上下文。
- 提升检索准确性。
缺点:
- 冗余增加内存使用。
示例:示例:
- 文本分块通过将文本分解成部分来提高检索。
- 重叠块(5 词重叠):
- 块 1:“分块通过分割提高检索”
- 块 2:“通过将文本拆分来检索”
- 块 3:“将文本拆分成部分。”
示例:示例:
Input: "The quick brown fox jumps over the lazy dog. It is a bright sunny day."
Overlap: 5 words
Chunks:
1. "The quick brown fox jumps over the lazy"
2. "fox jumps over the lazy dog. It is a"
3. "dog. It is a bright sunny day."- 影响:跨边界保持上下文,提高检索质量。
- 代码示例
def overlapping_chunk(text, size, overlap):
words = text.split()
chunks = []
for i in range(0, len(words), size - overlap):
chunks.append(" ".join(words[i:i+size]))
return chunks7. 字符文本分割
如何工作:如何工作
- 根据特定的字符限制分割文本。
优势:
- 快速且直接。
- 适用于具有令牌或字符限制的系统。
缺点:
- 风险在于字符在单词或句子中间掉落时破坏意义。
8. 使用 LangChain 进行自动文本分割
如何工作:如何工作
- 使用 LangChain 内置的
TextSplitter类来自动化分块。 - 根据文本类型和内容结构进行适配。
优势:
- 简化处理流程。
- 支持各种分块配置。
9. 递归字符文本分割
如何工作:如何工作
- 递归方法类似于递归字符分块,但专为分词文本设计。
10. 文档特定拆分
如何工作:如何工作
- 利用特定领域的拆分器(例如,
MarkdownSplitter、PythonCodeTextSplitter)来处理专业文档。
优势:
- 自定义各种格式的处理。
- 增强特定领域检索。
11. 基于嵌入的语义分块
如何工作:如何工作
- 使用语义嵌入将文本划分为连贯的片段。
- 将块与向量表示对齐以增强搜索。
12. 代理分块
代理分块关注逻辑命题或连贯的组群,将每个分块分解成有意义的行或组。
基于命题的词块化
- 解释:每个块代表一个逻辑命题,独立存在,具有完整的意义。
- 示例:示例:
Input: "The quick brown fox jumps. The lazy dog sleeps."
Chunks:
1. "The quick brown fox jumps."
2. "The lazy dog sleeps."影响:适用于结构化和基于规则的文本。
基于分组的分块
- 解释:根据代理驱动的启发式方法将相关块组合成连贯的单元。
- 代码示例
def agentic_chunk(text):
lines = text.split('. ')
chunks = [line.strip() + '.' for line in lines if line]
return chunks代理分块:详细解释

代理分块是一种复杂的文本分割策略,旨在确保文本块保持其语义连贯性并传达有意义的信息。它采用两种主要子策略:

基于命题的词块化
定义 基于命题的切分关注将文本分割成独立的块,其中每个部分代表一个命题或完整的想法。命题通常是一个句子或句子的一部分,传达一个完整的思想或陈述。
工作策略
命题识别
- 使用自然语言处理(NLP)技术,对文本进行分析以识别逻辑或语法命题。
- 例如,由连词或标点符号连接的从句可能被分成不同的命题。
分割过程
- 每个块都是为了确保它形成一个完整且独立的陈述,即使在孤立的情况下也能保留其意义。
语义完整性
- 该过程避免了以留下不完整或模糊信息的方式分割
示例:示例:
- 人工智能(AI)正在迅速发展,它正在改变着行业。
- 基于命题的词块
- 人工智能(AI)正在迅速发展。
- 它正在改变行业。
应用
- 在需要精确事实检索的系统中有用,例如知识库、问答系统和学术文本处理。
- 增强信息检索的粒度,确保每个片段提供完整的知识。
2. 使用代理分块器进行分组分块
定义 将信息分组成簇,通过将命题或句子分组到逻辑上、语义上一致的单位。目标是保持更广泛的上下文,同时将文本划分为可管理的块。
工作策略
识别关系
自然语言处理技术,如语义相似度和主题建模,被用于检测命题或句子之间的关系。
块形成:
相关命题被组合成一个单独的块。这可能是基于共享的主题、引用或逻辑流程。
尺寸优化
确保分组块不超过预定义的大小限制(例如,语言模型中的标记或字符限制)。
示例:示例:
- “人工智能正在迅速发展。它正在改变医疗保健和金融等行业。机器学习是人工智能的关键组成部分。”
- 分组块
- 块 1:“人工智能正在迅速发展。它正在改变医疗保健和金融等行业。”
- 机器学习是人工智能的关键组成部分。
应用
- 用于检索增强生成(RAG)系统,以生成保持更广泛上下文的具有意义的响应。
- 非常适合文档摘要,其中块之间的主题一致性至关重要。
代理分块的好处
语义一致性
- 确保每个片段都包含一个有意义的独立观点或语义上连贯的观点组。
改进检索准确性
- 通过关注逻辑单元,检索系统可以更好地与用户查询对齐。
上下文保留:
- 将块分组保留了多行推理任务所需的上下文。
灵活性
- 代理分块适应性强,适用于各种用例,从细粒度事实核查到更广泛的主题摘要。
挑战
计算开销
- 该过程涉及语义分析和自然语言处理计算,可能需要大量资源。
《块大小调整》
- 在粒度与上下文保留之间取得平衡需要仔细调整。
代码演示
设置环境
所需库使用以下命令安装:
pip install -U chromadb langchain llama-index langchain_experimental langchain_openai关键模块如用于美观打印的rich、用于文档和模型管理的langchain以及用于集成的langchain_community已被导入。使用 Mistral 模型初始化了本地LLM实例的ChatOllama类。
local_llm = ChatOllama(model="mistral")2. RAG 实现
RAG 函数使用一个向量存储(色度)和基于检索的提示策略。
- 嵌入式初始化:
OllamaEmbeddings模型生成文本嵌入,以实现高效的存储和检索。 - 检索器设置:向量存储作为检索器,根据查询搜索相关片段。
- 提示模板:一个自定义模板为LLM生成相关答案的问题和上下文进行框架。
def rag(chunks, collection_name):
vectorstore = Chroma.from_documents(
documents=documents,
collection_name=collection_name,
embedding=embeddings.ollama.OllamaEmbeddings(model='nomic-embed-text'),
)
retriever = vectorstore.as_retriever()
...
chain.invoke("What is the use of Text Splitting?")3. 文本分割技术
字符文本分割
文本手动分割成 35 个字符大小的块。或者,CharacterTextSplitter 通过可选参数如 chunk_size、chunk_overlap 和 separator 自动化此过程。
text_splitter = CharacterTextSplitter(chunk_size=35, chunk_overlap=0)
documents = text_splitter.create_documents([text])递归字符文本分割
这种方法智能地使用多个分隔符(例如,换行符、空格)来分割文本,以保持语义连贯。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=65, chunk_overlap=0)
documents = text_splitter.create_documents([text])4. 文档特定拆分
Markdown 分割
Markdown 特定的分割确保基于结构标记(如标题或列表)的逻辑分组。
splitter = MarkdownTextSplitter(chunk_size=40, chunk_overlap=0)
documents = splitter.create_documents([markdown_text])代码拆分
编程语言如 Python 和 JavaScript 根据语法进行划分,以保持功能性和可读性。
python_splitter = PythonCodeTextSplitter(chunk_size=100)
documents = python_splitter.create_documents([python_text])5. 高级语义分块
语义分块使用嵌入来计算句子之间的语义相似度,并根据预定义的阈值(例如,百分位数)进行分割。这确保了块在意义上被有意义地分隔。
from langchain_experimental.text_splitter import SemanticChunker
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type="percentile")
documents = text_splitter.create_documents([text])6. 代理分块
代理分块引入了基于命题的分块方法,其中句子或命题通过基于LLM的处理流程提取。这些命题使用AgenticChunker逻辑分组。
from agentic_chunker import AgenticChunker
ac = AgenticChunker()
ac.add_propositions(text_propositions)
chunks = ac.get_chunks(get_type='list_of_strings')
documents = [Document(page_content=chunk, metadata={"source": "local"}) for chunk in chunks]执行
代码最终将上述所有策略集成到一个 RAG 管道中。文本分割准备数据,而 RAG 函数使基于分割文档的问答变得高效。
rag(documents, "agentic-chunks")实施优势
- 可扩展性:LangChain 的文本拆分技术的模块化支持各种文档格式和用例。
- 精度:先进的分割策略,如语义和代理分块,确保高质量的分段。
- 与 RAG 集成:直接集成到基于检索的工作流程中,以增强性能。
参考:https://medium.com/@danushidk507/chunking-strategies-f93dbdec7634
联系我
最后,推荐大家关注一下开源项目:LangChat,Java生态下的AIGC大模型产品解决方案。
- LangChat产品官网:https://langchat.cn/
- Github: https://github.com/TyCoding/langchat
- Gitee: https://gitee.com/langchat/langchat
- 微信:LangchainChat